O que é AWS DynamoDB:
O DynamoDB é um serviço gerenciado oferecido pela Amazon Web Services para armazenagem de dados como chave-valor e documentos, com alto desempenho e escalabilidade.
Por ser considerado um banco de dados NoSQL, as tabelas no DynamoDB podem ter sua estrutura flexível, desde que sejam respeitados certos campos e tipos, como é o caso da chave composta. Isso facilita que várias linguagens de programação e frameworks se integrem muito bem a ele.
É claro que no DynamoDB as tabelas devem ser sempre projetadas tendo em mente as consultas que serão realizadas a seus itens, que é onde entram conceitos como chaves compostas e índices de pesquisa.
Este artigo mostra um exemplo de como uma aplicação, construída em Java e utilizando Spring Boot, pode acessar uma tabela criada no DynamoDB e realizar pesquisas utilizando chaves compostas.
Chave composta no DynamoDB:
As tabelas no DynamoDB podem ser organizadas, em relação a chave primária, de duas formas:
- Chave simples: aqui um atributo é elegido como a chave primária. Seu valor único determina a identificação do item na tabela.
- Chave composta: nesse modo, dois atributos compõem a chave primária, por isso chamada de composta. A associação dos valores desses atributos garantem a identificação única do item.
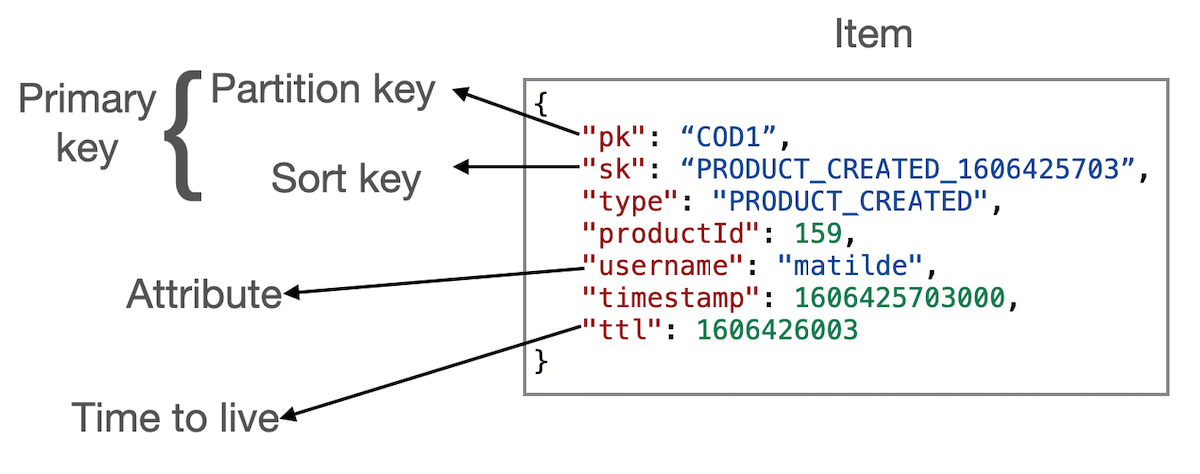
A chave composta, por sua vez, é construida por dois atributos que a define:
- Partition key: também conhecido como hash key, esse atributo define a partição dentro tabela do DynamoDB, onde os itens serão colocados. Numa explicação simplória, é como se fosse criada uma sub-tabela dentro da tabela principal, onde os dados poderiam ser pesquisados somente pelo valor da partition key.
- Sort key: também conhecido como range key, esse atributo permite pesquisas dentro da partição definida pela partition key, sem a necessidade de índices adicionais.
Como dito anteriormente, a estrutura da tabela do DynamoDB, principalmente da chave composta, deve ser pensada considerando as pesquisas que serão feitas em seus itens.
Para exemplificar melhor, imagine o cenário onde uma tabela do DynamoDB vai armazenar eventos de alteração em produtos, com as seguintes pesquisas possíveis:
- Buscar todos os eventos de alteração de um determinado produto, pelo seu código;
- Buscar todos os eventos de um determinado tipo, de um produto específico pelo seu código.
Essa tabela, de eventos de produtos, poderia ter a seguinte estrutura no DynamoDB:
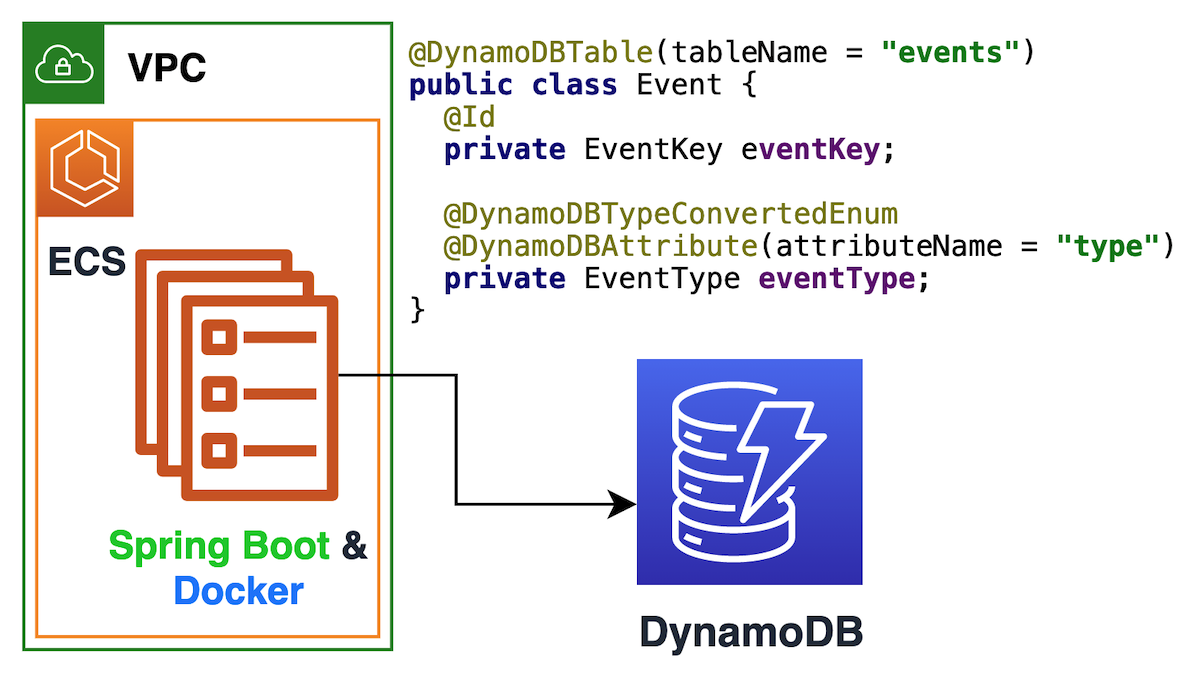
Perceba que os atributos pk e sk compõem a chave composta da tabela, que irão armazenar o código do produto e o tipo de evento, respectivamente. Isso possibilitará as pesquisas mencionadas acima.
No DynamoDB é possível pesquisar usando apenas a parte inicial do valor
da sort key, dentre outras operações.
No DynamoDB é possível pesquisar usando apenas a parte inicial do valor da sort key, dentre outras operações.
Os demais campos da tabela podem ter nomes e formatos diferentes, entre os itens, com exceção do ttl, que atua como um time-to-live para o item ser apagado automaticamente.
Essa será a tabela utilizada no exemplo desse artigo, que também irá mostrar como uma aplicação Spring Boot pode manipular os itens no DynamoDB com esse formato.
Adicionando bibliotecas ao Spring Boot:
Para começar a preparar o projeto Spring Boot para se trabalhar com o DynamoDB, é necessário
adicionar duas bibliotecas, como as que são mostradas no trecho a seguir, que devem ser
inseridas no arquivo build.gradle, na seção dependencies:
As duas últimas bibliotecas nesse trecho são, respectivamente:
- A biblioteca do SDK da AWS para o DynamoDB;
- Uma biblioteca não-oficial do Spring Data para o DynamoDB, que facilita, e muito, o trabalho de operações no DynamoDB quando se tem modelos como o que será criado a seguir.
Configurando o Spring Boot:
Agora é possível configurar a aplicação Spring Boot para acessar o DynamoDB. Para isso,
primeiramente crie a variável no arquivo applications.properties para
representar
a região da Amazon Web Services onde a aplicação irá ser executada:
Essa variável pode ser preenchida em tempo de execução, através de parâmetros passados para a definição da tarefa do AWS ECS, por exemplo.
Se quiser aprender como construir uma aplicação para ser executada no
AWS ECS, consulte esse tutorial.
Se quiser aprender como construir uma aplicação para ser executada no AWS ECS, consulte esse tutorial.
Agora, crie uma classe de configuração para que o Spring Boot possa acessar a tabela do DynamoDB, como no trecho a seguir:
Perceba que a classe é anotada com @Configurarion, o que indica ao Spring Boot
que ela deve ser executada assim que a aplicação for inicializada, no momento de sua
configuração.
Também existe a anotação @EnableDynamoDBRepositories, onde é passada a interface
ProductEventLogRepository, que será criada mais adiante. Nessa interface serão
definidos os métodos de pesquisa que poderão ser feitos na tabela do DynamoDB, para um
modelo específico. Aqui várias interfaces poderiam ser passadas, como uma lista, se o
projeto tiver outros modelos.
O atributo que representa a região da AWS em que a aplicação está sendo executada aparece
aqui como um atributo da classe, recebendo o valor inserido em
application.properties.
Nessa mesma classe, crie o bean de configuração do cliente do DynamoDB:
A opção DEFAULT pode ser muito bem utilizada nesse caso, que possui opções para
paginação e leituras consistentes no modo eventual.
Ainda nessa classe, crie um outro bean com a configuração do mapper dos
modelos de objetos que podem ser criados no projeto:
Veja que ele recebe 2 parâmetros: o cliente do DynamoDB e um objeto de configuração, que foi criado anteriormente.
O cliente do DynamoDB deve ser criado nessa classe como um bean, como no trecho
a seguir:
Basicamente o cliente é construído com a informação de onde estão as credenciais de acesso ao DynamoDB, que podem estar atribuidas à tarefa do ECS, e a região onde a aplicação está sendo executada.
Criando o modelo da chave composta:
Como mencionado anteriormente nesse artigo, a tabela que irá armazenar os eventos de produtos no DynamoDB terá uma chave composta. Para isso, é necessário definir um modelo no projeto com o Spring Boot, como no trecho a seguir:
Os dois atributos da classe levam os nomes dos atributos da tabela do DynamoDB que farão
parte da chave composta, nesse caso pk e sk, abreviações de partition
key e sort key, respectivamente.
Os nomes dos atributos da chave composta podem ser diferentes, mas pk
e sk ficam genéricos, facilitando a adoção da mesma tabela para outros eventos.
Os nomes dos atributos da chave composta podem ser diferentes, mas pk e sk ficam genéricos, facilitando a adoção da mesma tabela para outros eventos.
Essa classe será utilizada como o tipo da chave composta, no modelo do item do DynamoDB.
Criando o modelo do para representar a tabela no DynamoDB:
Agora é possível criar o modelo que irá de fato representar o evento na tabela do DynamoDB. Para isso, crie uma nova classe como no trecho a seguir:
O primeiro ponto a ser notado aqui é a anotação @DynamoDBTable. Ela denota um
modelo que representa uma tabela no DynamoDB, que tem seu nome definido no atributo tableName,
que nesse caso recebe o valor events. Logo, esse será o nome da tabela do DynamoDB
que receberá os eventos de produtos.
O parâmetro EventKey, definido no modelo criado anteriormente, define a chave
primária, aqui anotada com @Id.
Ainda podem ser criados outros atributos nessa classe para representar mais dados no item no
DynamoDB, como eventType, que foi colocado aqui como exemplo.
Nessa classe, os getters e setters dos atributos pk e
sk merecem um pouco
de atenção e trabalho, como no trecho a seguir:
Os getters devem ser anotados com as mesmas anotações utilizadas no modelo
Event definido anteriormente.
Se algum dia for necessário adicionar um novo atributo na tabela, basta
adicionar um novo atributo nessa classe.
Se algum dia for necessário adicionar um novo atributo na tabela, basta adicionar um novo atributo nessa classe.
Criando o repositório no Spring Boot:
Com a definição do modelo do item da tabela no DynamoDB, é possível criar uma interface para representar os métodos que podem ser utilizados, ao estilo do Spring Data:
Veja que essa interface estende de CrudRepository, que garante que alguns
métodos de acesso já estarão prontos, como save e findById.
Aqui os modelos Event e EventKey são passados, como o modelo e o
tipo de sua chave primária.
Logo em seguida, ainda nessa interface, o método findAllByPk é definido para
fazer buscas de todos os eventos de produtos a partir de seu código, que nesse caso foi
guardado no atributo pk. Essa pesquisa é feita na partition key da
chave composta da tabela.
Também foi definido o método findAllByPkAndSkStartsWith, que recebe o valor da
pk, que nesse caso é o código do produto, e o tipo do evento, que está
armazenado na sk. Porém, como mostrado anteriormente, esse atributo terá seu
valor concatenado com um timestamp, para deixá-lo único. Isso significa que deve-se
pesquisar somente pelo começo desse valor, através da expressão StartsWith.
Como essas duas pesquisas são feitas na chave composta, a operação na tabela do DynamoDB será
do tipo query, evitando assim um scan, que varreria toda a tabela.
Utilizando o repositório para operações no DynamoDB:
Para persistir dados na tabela com esse repositório que foi criado, basta acessar a operação
save de uma instância dele:
eventRepository.save(event)
E para pesquisar eventos utilizando os dois métodos que foram criados na interface, basta passar os atributos que eles necessitam:
eventRepository.findAllByPk(code)
E também:
eventRepository.findAllByPkAndSkStartsWith(code, event)
Os dois métodos retornar uma lista dos eventos que foram encontrados na tabela
events do DynamoDB, sem fazer scan.
Conclusão:
Utilizar uma abstração do Spring Data com tabelas do DynamoDB torna o trabalho muito produtivo em uma aplicação com Spring Boot, sem perder as vantagens desse tipo de serviço.
É claro que algumas funcionalidades podem ser um pouco mais complexas para serem implementadas, como por exemplo a escrita de somente alguns atributos, sem a necessidade de se persistir todo o item novamente, mas isso pode ser facilmente contornado com a criação de outros modelos que representem somente esses atributos.
Se você gostou desse conteúdo, siga-me no LinkedIn, para receber notificações de outros tutoriais como esse!
Referência:
Esse artigo foi baseado nos conceitos ministrados nesse curso online: Curso criando microsserviços em Java com AWS ECS e Fargate
Quem sou eu:
- Trabalhei diariamente com as tecnologias apresentadas nesse blog por quase 4 anos, atuando como desenvolvedor de soluções hospedadas na Amazon Web Services;
- Tenho lecionado disciplinas de cloud computing, principalmente AWS, em curso de pós-graduação há quase 10 anos;
- Tenho livros publicados sobre o assunto;
- Faço parte da comunidade global AWS Community Builder 2020/2021/2022, criada pela própria AWS.